Entendendo a Consistência em Sistemas Distribuídos
Neste artigo descomplicaremos o conceito de consistência em sistemas distribuídos e te ajudar a escolher o banco de dados ideal.
Em sistemas distribuídos, manter todo mundo na mesma página pode ser um baita desafio: cada nó do sistema pode estar em um lugar diferente, com tempos de resposta variados. Se os dados não estiverem sincronizados, pronto: lá vem confusão e possíveis falhas.
Entender a lógica por trás da consistência é essencial para escolher a tecnologia ideal e evitar dores de cabeça de arquitetura. E é exatamente isso que vamos fazer agora: vamos descomplicar esse conceito de uma vez por todas e ajudar você a escolher o banco de dados ideal para os seus projetos.
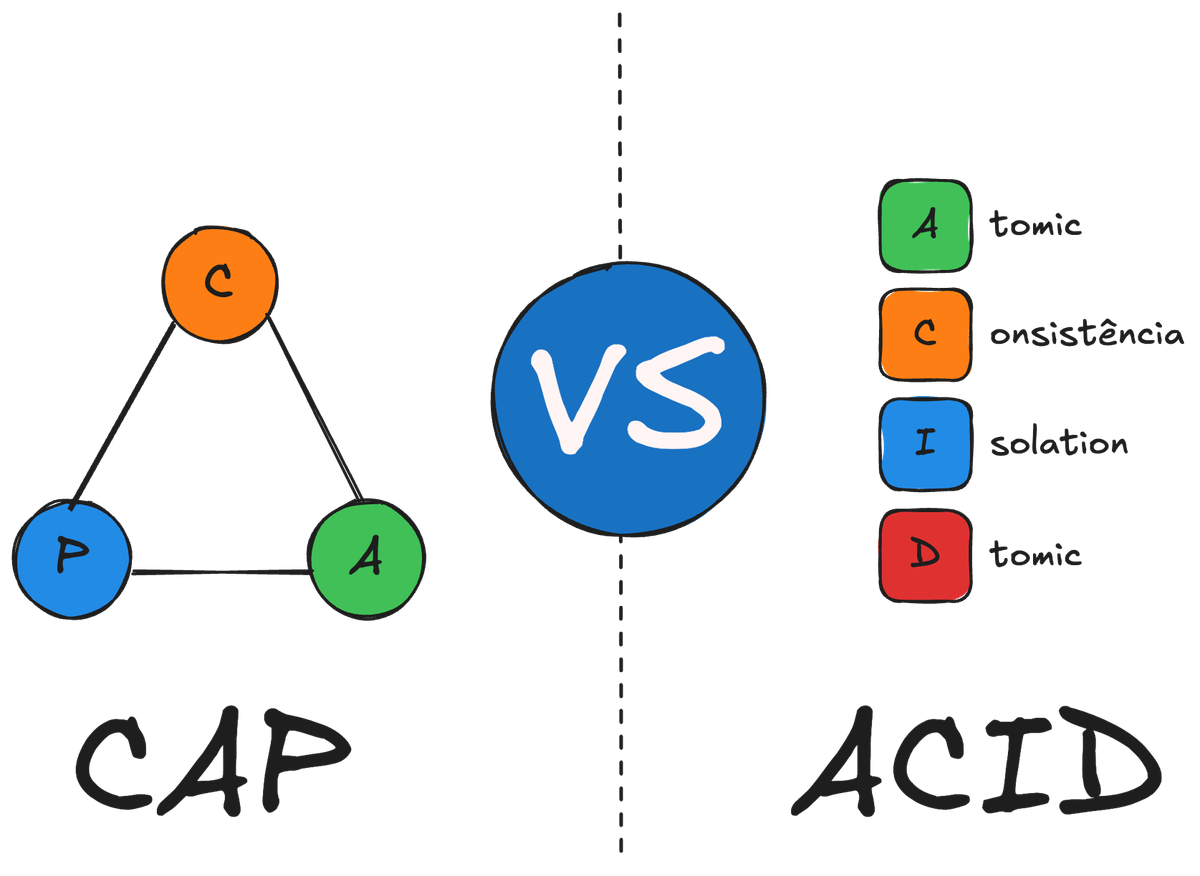
CAP vs ACID
Imagine o seguinte, você é um engenheiro de software super antenado nas tendências e recebe uma missão: construir uma plataforma de pagamento que exige dados 100% atualizados em qualquer operação. Claro que você sabe que, em alguns casos, consistência é crucial — afinal, não dá para mostrar um saldo “velho” na hora de validar transações financeiras, certo?
Mas, numa conversa com colegas do café, ele escuta: “Cara, vai de MongoDB! É a sensação do momento e ainda tem suporte a transações multi-documento, tipo ACID. Você mata dois coelhos com uma cajadada só: modernidade e consistência top de linha!” Sem perder tempo, você se joga no hype e escolhe MongoDB para o projeto e avisa o time: “Podem ficar tranquilos, a gente tá seguro. É ACID!”
O dilema surge
Quando a plataforma começa a escalar, as leituras precisam ser distribuídas para melhorar performance. A ideia: usar réplicas secundárias do MongoDB. Tudo lindo no papel. Só que, de repente, chegam reclamações de clientes:
- Alguém consulta o saldo e vê um valor antigo, mesmo depois de ter feito um depósito minutos antes.
- Outro cliente diz que conseguiu aprovar uma compra, porém o sistema aponta um saldo diferente em duas telas distintas.
A dura realidade
Você investiga e percebe que ao ler dados de nós secundários, o sistema está sujeito a atrasos na replicação — o famoso “a consistência eventual”. Então, mesmo com transações multi-documento, essa “consistência” desaparece quando a leitura é feita em um nó que ainda não aplicou a atualização.
Nesse momento você aprende da forma mais difícil que a consistência do ACID, não é exatamente a mesma do CAP e você paga o preço por apostar no hype. E que a consistência do ACID trata de integridade e respeito às regras de negócio dentro de transações. Já a consistência do CAP foca em como todos os nós de um sistema distribuído veem o mesmo estado de dados.
Não é raro encontrarmos conteúdos dizendo que esses conceitos são a mesma coisa. E é aí que entra o Teorema CAP, fundamental para entendermos de vez por que ACID nem sempre significa consistência forte em sistemas distribuídos.
Teorema CAP
O Teorema CAP (Consistency, Availability e Partition Tolerance) diz que em um sistema distribuído, você pode priorizar apenas dois desses três pilares de forma plena. O “C” aqui vem de consistência, que nesse contexto significa que, em qualquer nó do sistema, as leituras de dados devem refletir sempre o último estado confirmado (ou seja, todo mundo tem a mesma visão do dado). Em outras palavras, se alguém atualiza um registro, qualquer um que ler esse registro em seguida vai ter a versão mais recente.
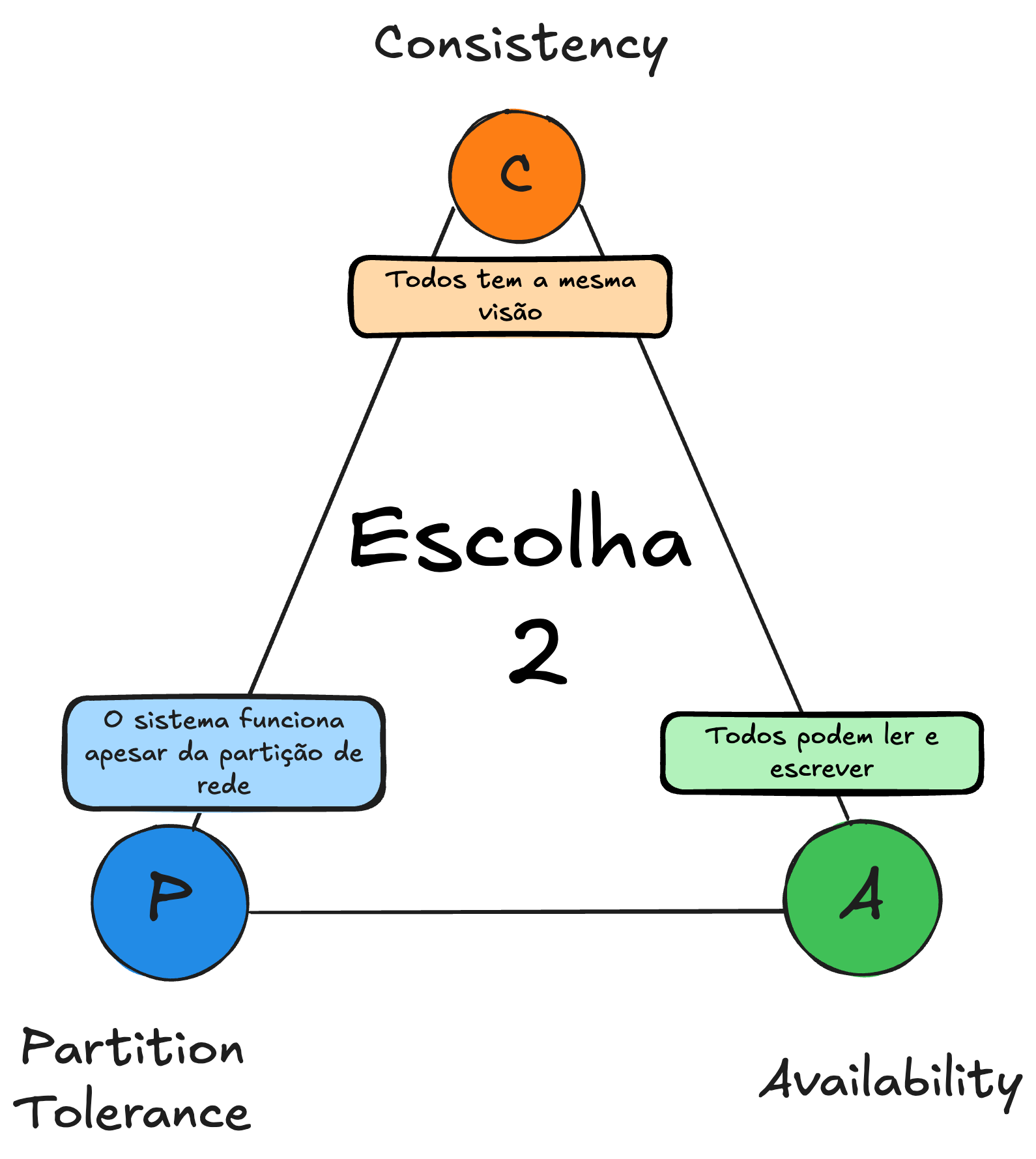
Porém, se você sofre uma partição na rede (perda de conexão entre alguns nós), tem que escolher entre manter a consistência absoluta ou a disponibilidade (continuar respondendo solicitações mesmo com dados possivelmente defasados). Em muitos casos, é preferível sacrificar um pouco de consistência para manter o sistema sempre no ar (ou vice-versa, a depender do cenário).
Propriedades ACID
As Propriedades ACID (Atomicity, Consistency, Isolation, Durability) vêm de um cenário de bancos de dados transacionais. Pense em uma transação bancária: se você transfere R$100 para um amigo, esse valor deve sair completamente da sua conta e aparecer na conta dele de forma integral. Não pode duplicar, não pode cair pela metade e tampouco gerar dados inválidos.
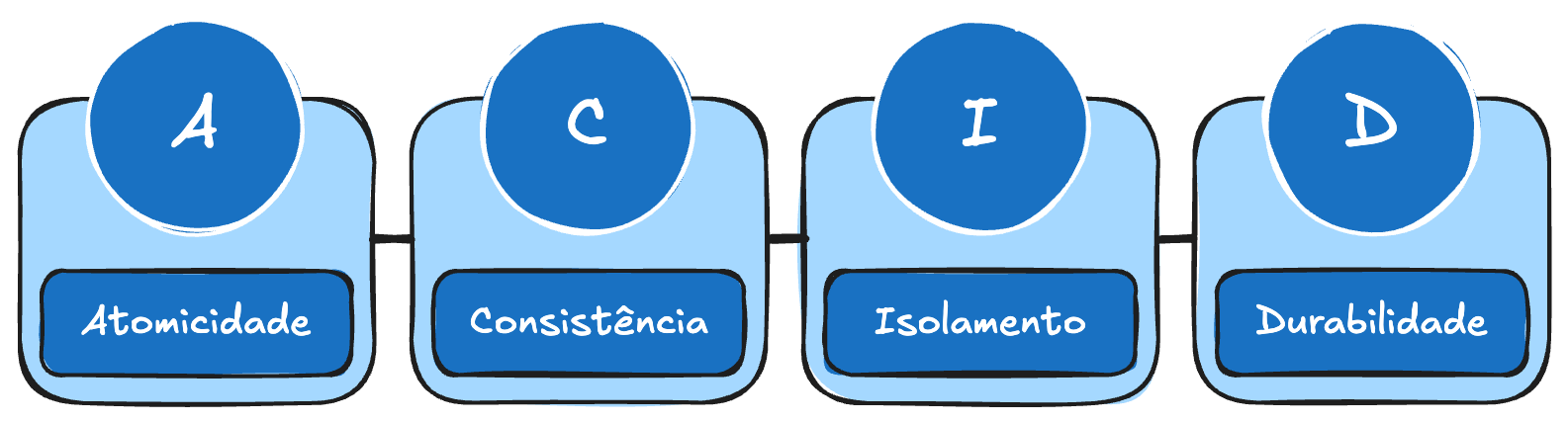
- Atomicity: ou tudo ou nada.
- Consistency: não pode corromper dados nem violar regras de integridade.
- Isolation: uma transação não pode interferir em outra de maneira suja.
- Durability: uma vez confirmada, a transação persiste mesmo que haja falha de energia, de rede etc.
Repare que “consistência” no ACID tem mais a ver com a garantia de integridade e regras de negócio. Já no CAP, é aquela garantia de que todo nó do sistema refletirá o mesmo estado de dados. São dois contextos distintos de “consistência”. No CAP, é uma consistência mais orientada a réplicas e acesso concorrente em múltiplos nós. No ACID, é uma consistência focada em constraints e transações dentro de um banco de dados (que pode até ser distribuído, mas geralmente pensamos em um RDBMS tradicional).
Tipos de Consistência em Sistemas Distribuídos
Agora que já diferenciamos CAP e ACID, vamos aprofundar nos tipos de consistência que surgem em sistemas distribuídos. A ideia geral é: quanto mais “rígida” a consistência, maior o custo de comunicação e bloqueios no sistema; quanto mais “flexível”, maior a disponibilidade, mas mais cuidado você deve ter com leituras possivelmente desatualizadas.
1. Consistência Forte (Strong Consistency)
Na Consistência Forte, também chamada de linearizabilidade, toda leitura de dados reflete o último estado confirmado globalmente. Significa que, ao escrever um valor em um nó, qualquer outro nó que fizer leitura desse dado em seguida receberá imediatamente a versão mais recente (mesmo considerando o atraso físico da rede). É como se todos estivessem sincronizados em um mesmo “presente”.
- Vantagem: todos veem os mesmos dados o tempo todo, eliminando divergências.
- Desvantagem: é mais custoso e aumenta a latência, pois o sistema precisa garantir que todos os nós estejam atualizados antes de responder a qualquer leitura.
- Exemplo de uso: serviços bancários críticos, como mostrar o saldo de uma conta; se você precisa ter a certeza de que todos visualizam sempre o saldo atualizado, essa consistência forte compensa o custo de coordenação extra, evitando inconsistências financeiras.
2. Consistência Eventual (Eventual Consistency)
Na Consistência Eventual, a ideia é que, se não houver nenhuma atualização nova por tempo suficiente, em algum momento todos os nós convergirão para o mesmo estado. Porém, durante o processo, leituras podem retornar versões diferentes do dado.
- Vantagem: altíssima disponibilidade e baixa latência, pois os nós não precisam ficar travados esperando confirmação de todo mundo.
- Desvantagem: você pode ler dados “antigos” ou “inconsistentes” temporariamente.
Exemplo de uso: o serviço de e-mails distribuído, em que receber e enviar mensagens deve ser rápido e tolerar falhas. Se um nó ficar offline por algum motivo, quando voltar, sincroniza as mensagens que ficaram “desalinhadas”. Facebook, Twitter e outros grandes sistemas também usam consistência eventual em muitas partes do sistema, pois é mais importante responder rápido do que ter sempre a última versão do “like” de um post.
3. Consistência Causal (Causal Consistency)
A Consistência Causal garante a ordem de eventos que estão causalmente relacionados. Se A influenciar B (ex.: primeiro publico algo, depois você comenta), o sistema deve preservar essa sequência. Entretanto, dois eventos sem relação direta (como eu mudar minha foto de perfil e você curtir a foto de outra pessoa) podem ter ordenações diferentes para cada nó.
- Vantagem: fornece um equilíbrio interessante, pois apenas eventos relacionados precisam manter ordem.
- Desvantagem: implementação mais complexa que a eventual pura, e ainda não entrega a visão “forte” global para todos.
Exemplo de uso: serviços de chat distribuído ou aplicativos colaborativos, onde a ordem das mensagens que se referem entre si deve fazer sentido (resposta a uma pergunta), mas não precisamos sincronizar toda a timeline de todo mundo globalmente.
Casos de Uso: Qual Consistência Escolher?
A decisão de escolher o tipo de consistência não é trivial, pois depende do modelo de negócios, dos requisitos de latência, disponibilidade e tolerância a falhas.
- Consistência Forte:
- Caso de uso: Sistemas financeiros, operações de stock exchange, controle de inventário em tempo real onde não se pode vender o que não tem.
- Por que escolher: Garante precisão absoluta no estado dos dados.
- Alerta: prepare-se para custos de rede mais elevados e possíveis bloqueios durante sincronizações.
- Consistência Eventual:
- Caso de uso: Aplicativos de mensagens, jogos online, caches de conteúdo (CDNs), redes sociais massivas onde a latência deve ser mínima.
- Por que escolher: Escalabilidade e disponibilidade são enormes, pois cada nó pode funcionar independentemente.
- Alerta: seu sistema precisa tolerar leituras desatualizadas ou divergências temporárias.
- Consistência Causal:
- Caso de uso: Chats, documentos colaborativos, sistemas de comentários em thread (ex.: GitHub Issues, Slack) em que a ordem das respostas está conectada a uma mensagem anterior.
- Por que escolher: Preserva a ordem lógica dos eventos relacionados, sem precisar sincronizar tudo.
- Alerta: a implementação é mais complexa e nem todo sistema tem eventos causalmente conectados que justifiquem esse esforço.
Conclusão
Consistência forte garante que todos tenham a mesma informação antes de qualquer ação, mas pode causar atrasos. Já a consistência eventual permite maior agilidade, porém corre o risco de dados defasados momentaneamente. A escolha depende do tipo de aplicação (por exemplo, um “banco digital” versus um “feed de redes sociais”), do nível de disponibilidade desejado e da precisão necessária para os dados.
Portanto, entender as nuances de CAP, ACID e dos diferentes modelos de consistência é essencial para projetar sistemas distribuídos confiáveis, escaláveis e alinhados às demandas do negócio.